एक्सेल में जेड-स्कोर की गणना कैसे करें: एक व्यापक गाइड
सांख्यिकी और डेटा विश्लेषण के क्षेत्र में, यह समझना महत्वपूर्ण है कि आपका डेटा औसत से कैसे तुलना करता है। एक z-स्कोर, जिसे मानक स्कोर के रूप में भी जाना जाता है, एक डेटासेट के माध्य से डेटा बिंदु की सापेक्ष दूरी को मापने का एक तरीका प्रदान करता है, जिसे मानक विचलन के रूप में व्यक्त किया जाता है। चाहे आप परीक्षण स्कोर, वित्तीय डेटा, या किसी अन्य संख्यात्मक डेटासेट का विश्लेषण कर रहे हों, z स्कोर की गणना आपके डेटा के व्यवहार में गहन अंतर्दृष्टि प्रदान कर सकती है।
|
ज़ेड-स्कोर की गणना करने के लिए एक्सेल का उपयोग करना सरलता और दक्षता प्रदान करता है, जिससे मानकीकृत तुलना और बाहरी पहचान के लिए बड़े डेटासेट का त्वरित विश्लेषण सक्षम हो जाता है। यह ट्यूटोरियल आपको यह समझने में मार्गदर्शन करेगा कि z-स्कोर क्या है, इसे Excel में कैसे खोजें, सूत्र उदाहरण प्रदान करें, अपने डेटा में z स्कोर की व्याख्या करें, और इन गणनाओं को निष्पादित करते समय याद रखने योग्य महत्वपूर्ण युक्तियाँ साझा करें। |
 |
z-स्कोर क्या है?
एक z-स्कोर, जिसे मानक स्कोर के रूप में भी जाना जाता है, एक सांख्यिकीय मीट्रिक है जो मानक विचलन के संदर्भ में व्यक्त डेटासेट के माध्य से एक विशिष्ट डेटा बिंदु की दूरी की मात्रा निर्धारित करता है। यह माप यह समझने के लिए महत्वपूर्ण है कि डेटा बिंदु डेटासेट के औसत मूल्य से कितनी दूर और किस दिशा में (ऊपर या नीचे) विचलित होता है। संक्षेप में, एक z-स्कोर डेटा बिंदुओं को एक सामान्य पैमाने पर बदल देता है, जिससे माप या वितरण आकार के मूल पैमाने की परवाह किए बिना, विभिन्न डेटासेट में या विविध आबादी के भीतर सीधी तुलना की अनुमति मिलती है।
|
जेड-स्कोर की अवधारणा सामान्य वितरण के साथ घनिष्ठ रूप से जुड़ी हुई है। सामान्य वितरण आंकड़ों में एक मौलिक अवधारणा है, जो एक ऐसे वितरण का प्रतिनिधित्व करता है जहां अधिकांश अवलोकन केंद्रीय शिखर के आसपास क्लस्टर होते हैं और मूल्यों के घटित होने की संभावनाएं माध्य से दोनों दिशाओं में सममित रूप से कम हो जाती हैं। सामान्य वितरण के संदर्भ में: |
|

- लगभग 68% डेटा माध्य के एक मानक विचलन (±1 z-स्कोर) के भीतर आता है, जो औसत से मध्यम विचलन का संकेत देता है।
- लगभग 95% अवलोकन दो मानक विचलनों (±2 z-स्कोर) के भीतर हैं, जो एक महत्वपूर्ण लेकिन चरम विचलन नहीं दिखाते हैं।
- लगभग 99.7% डेटा तीन मानक विचलनों (±3 z-स्कोर) के भीतर पाया जाता है, जो एक वितरण के भीतर लगभग सभी टिप्पणियों को शामिल करता है और अत्यधिक विचलन को उजागर करता है।
ज़ेड-स्कोर सांख्यिकीय विश्लेषण में एक महत्वपूर्ण उपकरण है, जो शोधकर्ताओं और विश्लेषकों को अलग-अलग डेटासेट से व्यक्तिगत टिप्पणियों को मानकीकृत करने में सक्षम बनाता है, जिससे अलग-अलग वितरणों से स्कोर की तुलना की सुविधा मिलती है। डेटा को z-स्कोर में परिवर्तित करके, कोई आसानी से यह निर्धारित कर सकता है कि किसी दिए गए वितरण के भीतर कोई विशेष अवलोकन कितना असामान्य या विशिष्ट है, जिससे यह बाहरी पहचान, परिकल्पना परीक्षण और डेटा सामान्यीकरण सहित विभिन्न अनुप्रयोगों के लिए एक अनिवार्य उपकरण बन जाता है।

एक्सेल में z-स्कोर कैसे खोजें?
एक्सेल में, सीधे z-स्कोर की गणना के लिए कोई एकल, समर्पित फ़ंक्शन नहीं है। इस प्रक्रिया में आपके डेटासेट के माध्य की प्रारंभिक गणना शामिल है (μ) और मानक विचलन (σ). इन आवश्यक आँकड़ों को प्राप्त करने के बाद, आपके पास z-स्कोर निर्धारित करने के लिए दो प्राथमिक विधियाँ हैं:
- मैन्युअल गणना विधि: z-स्कोर फॉर्मूला लागू करें:
=(x-μ)/σ - जहाँ:
- x वह डेटा बिंदु है जिसकी आप जांच कर रहे हैं,
μ आपके डेटासेट का माध्य है,
σ आपके डेटासेट का मानक विचलन है। - मानकीकरण फ़ंक्शन का उपयोग करना: अधिक एकीकृत दृष्टिकोण के लिए, एक्सेल प्रमाण के अनुसार करना फ़ंक्शन इनपुट के रूप में डेटा बिंदु, माध्य और मानक विचलन को सीधे देखते हुए z-स्कोर की गणना करता है:
=STANDARDIZE(x, mean, standard_dev)
Excel में z-स्कोर की गणना करने के लिए सूत्र उदाहरण
मान लें कि आपके पास कॉलम ए में कोशिकाओं से फैला हुआ डेटासेट है A2 सेवा मेरे A101, यहां बताया गया है कि आप इन मानों के लिए z-स्कोर की गणना कैसे करेंगे:
- माध्य की गणना करें (μ): उपयोग औसत(सीमा) माध्य ज्ञात करने का कार्य (μ) आपके डेटासेट का।
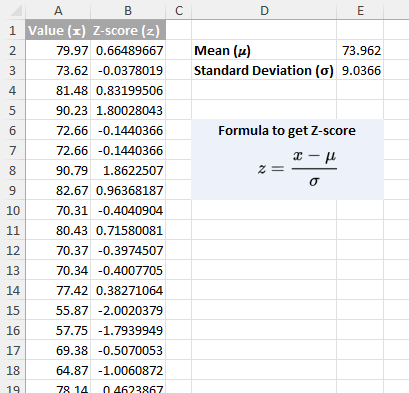
=AVERAGE(A2:A101)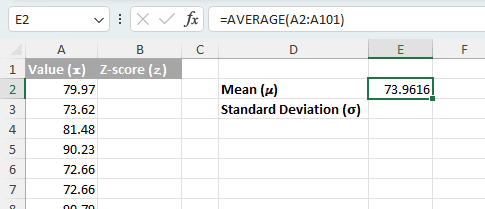
- मानक विचलन की गणना करें (σ): अपने डेटा संदर्भ के आधार पर उपयुक्त सूत्र का चयन करें।
महत्वपूर्ण: सटीक गणना सुनिश्चित करने के लिए अपने डेटासेट के लिए सही फ़ंक्शन चुनना महत्वपूर्ण है। (मेरे डेटा के लिए A2: A101 संपूर्ण जनसंख्या का प्रतिनिधित्व करते हुए, मैं पहले सूत्र का उपयोग करूंगा।)
- उपयोग एसटीडीईवी.पी(रेंज) कार्य करें यदि आपका डेटा संपूर्ण जनसंख्या का प्रतिनिधित्व करता है (मतलब कोई बड़ा समूह नहीं है जिससे ये मान नमूना लिए गए हैं)।
=STDEV.P(A2:A101) - उपयोग एसटीडीईवी.एस(रेंज) यदि आपका डेटा एक बड़ी जनसंख्या का नमूना है या आप अपने नमूने के आधार पर जनसंख्या मानक विचलन का अनुमान लगाना चाहते हैं तो कार्य करें।
=STDEV.S(A2:A101)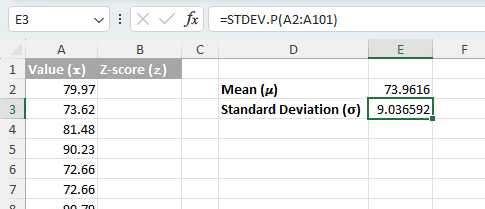
- उपयोग एसटीडीईवी.पी(रेंज) कार्य करें यदि आपका डेटा संपूर्ण जनसंख्या का प्रतिनिधित्व करता है (मतलब कोई बड़ा समूह नहीं है जिससे ये मान नमूना लिए गए हैं)।
- A2 में डेटा पॉइंट के लिए Z-स्कोर की गणना करें: निम्नलिखित में से किसी एक सूत्र का उपयोग करें, जिससे समान परिणाम प्राप्त होगा। (इस उदाहरण में, मैं दूसरा फॉर्मूला चुनूंगा।)
- मैन्युअल रूप से गणना करें डेटा बिंदु से माध्य घटाकर और इस परिणाम को मानक विचलन से विभाजित करके।
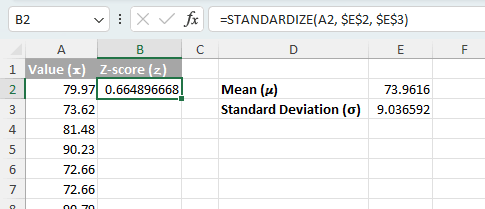
=(A2 - $E$2) / $E$3 - उपयोग मानकीकरण(x, माध्य, मानक_देव) समारोह.
=STANDARDIZE(A2, $E$2, $E$3)नोट: डॉलर के संकेत ($) हमेशा विशिष्ट कोशिकाओं को संदर्भित करने के लिए सूत्र बताएं (E2 मतलब के लिए, E3 मानक विचलन के लिए) भले ही सूत्र की प्रतिलिपि बनाई गई हो।
- मैन्युअल रूप से गणना करें डेटा बिंदु से माध्य घटाकर और इस परिणाम को मानक विचलन से विभाजित करके।
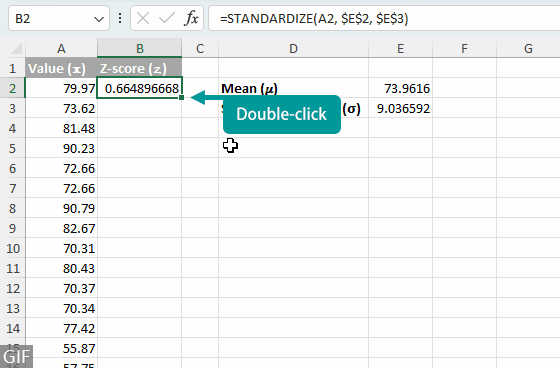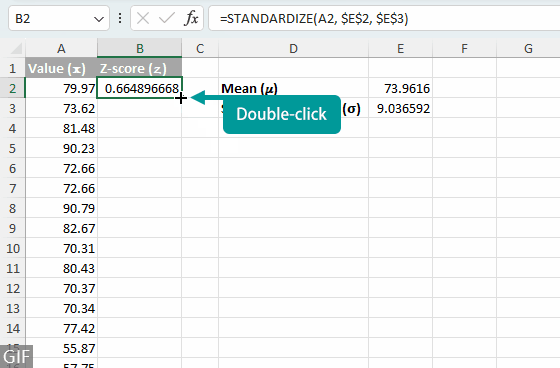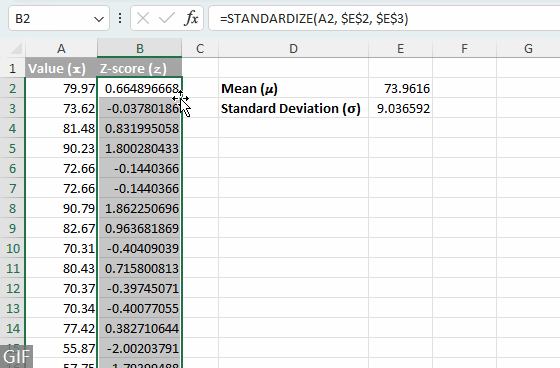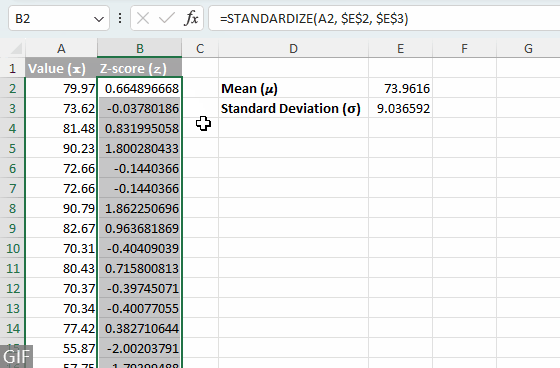
- अपने डेटासेट में प्रत्येक मान के लिए Z-स्कोर की गणना करें: अपने डेटासेट में प्रत्येक मान के लिए z-स्कोर की गणना करने के लिए चरण 3 में सूत्र को कॉलम के नीचे कॉपी करें। सुझाव: सूत्र को शीघ्रता से विस्तारित करने के लिए सेल के भरण हैंडल पर डबल-क्लिक करें।
- अलग-अलग कोशिकाओं में माध्य और मानक विचलन के लिए अलग-अलग फ़ार्मुलों को टाइप किए बिना संपूर्ण डेटासेट में z-स्कोर की अपनी गणना को सुव्यवस्थित करने के लिए, आप निम्नलिखित व्यापक फ़ार्मुलों में से किसी एक को सीधे नियोजित कर सकते हैं।
=(A2 - AVERAGE($A$2:$A$101)) / STDEV.P($A$2:$A$101)=STANDARDIZE(A2, AVERAGE($A$2:$A$101), STDEV.P($A$2:$A$101)) - ज़ेड-स्कोर के लिए तीन दशमलव स्थानों का उपयोग करके लगातार सटीकता बनाए रखना वैज्ञानिक और सांख्यिकीय कार्यों में एक सराहनीय अभ्यास है। अपने z-स्कोर सेल का चयन करके और इसका उपयोग करके इसे प्राप्त करें दशमलव घटाएं में विकल्प मिला नंबर पर समूह होम टैब.
डेटा में z-स्कोर की व्याख्या करना
डेटासेट के भीतर डेटा बिंदुओं की स्थिति और महत्व को समझने के लिए z-स्कोर की व्याख्या करना मौलिक है। एक z-स्कोर एक प्रत्यक्ष माप प्रदान करता है कि कोई तत्व डेटासेट के माध्य से कितने मानक विचलन है, जो इसकी सापेक्ष स्थिति और दुर्लभता में अंतर्दृष्टि प्रदान करता है।
माध्य से संबंध
- Z-स्कोर = 0: औसत प्रदर्शन को दर्शाता है, डेटा बिंदु बिल्कुल माध्य पर है।
- Z-स्कोर > 0: औसत से अधिक मूल्यों को दर्शाता है, माध्य से अधिक दूरी मजबूत प्रदर्शन का संकेत देती है।
- Z-स्कोर < 0: औसत से नीचे के मूल्यों का प्रतिनिधित्व करता है, जहां कम स्कोर औसत से नीचे अधिक विचलन को दर्शाता है।
विचलन की डिग्री
- |जेड-स्कोर| <1: ये डेटा बिंदु औसत के करीब हैं, सामान्य वितरण में डेटा के मुख्य निकाय के भीतर आते हैं, जो मानक प्रदर्शन का संकेत देते हैं।
- |जेड-स्कोर| <2: माध्य से मध्यम विचलन का सुझाव देता है, अवलोकनों को असामान्य लेकिन फिर भी भिन्नता की सामान्य सीमा के भीतर चिह्नित करता है।
- |जेड-स्कोर| > 2: औसत से काफी दूर असामान्य डेटा बिंदुओं को हाइलाइट करता है, संभावित रूप से अपेक्षित मानदंड से आउटलेयर या पर्याप्त विचलन का संकेत देता है।
उदाहरण स्पष्टीकरण:
- 0.66 के z-स्कोर का मतलब है कि डेटा बिंदु माध्य से 0.66 मानक विचलन ऊपर है। यह इंगित करता है कि मूल्य औसत से अधिक है लेकिन अभी भी इसके अपेक्षाकृत करीब है, जो भिन्नता की विशिष्ट सीमा के भीतर आता है।
- इसके विपरीत, -2.1 का z-स्कोर दर्शाता है कि डेटा बिंदु माध्य से 2.1 मानक विचलन नीचे है। यह मान औसत से काफी कम है, जो दर्शाता है कि यह सामान्य सीमा से और भी दूर है।
Excel में z-स्कोर की गणना करते समय याद रखने योग्य बातें
ज़ेड-स्कोर की गणना के लिए एक्सेल का उपयोग करते समय, परिशुद्धता और सटीकता सर्वोपरि होती है। आपके परिणामों की विश्वसनीयता सुनिश्चित करने के लिए ध्यान में रखने योग्य महत्वपूर्ण बातें हैं:
- सामान्य वितरण की जाँच करें: सामान्य वितरण का पालन करने वाले डेटा के लिए Z-स्कोर सबसे प्रभावी होते हैं। यदि आपका डेटासेट इस वितरण का पालन नहीं करता है, तो z-स्कोर एक उपयुक्त विश्लेषणात्मक उपकरण के रूप में काम नहीं कर सकता है। ज़ेड-स्कोर विश्लेषण लागू करने से पहले एक सामान्यता परीक्षण आयोजित करने पर विचार करें।
- सही फ़ॉर्मूला उपयोग सुनिश्चित करें: सुनिश्चित करें कि आपने सही मानक विचलन फ़ंक्शन का चयन किया है - STDEV.P संपूर्ण आबादी के लिए और STDEV.S नमूनों के लिए - आपके डेटासेट विशेषताओं के आधार पर।
- माध्य और मानक विचलन के लिए निरपेक्ष संदर्भ का उपयोग करें: एकाधिक कक्षों में सूत्र लागू करते समय, निरपेक्ष संदर्भों का उपयोग करें (उदाहरण के लिए, $ए$1) गणनाओं में एकरूपता सुनिश्चित करने के लिए आपके z-स्कोर सूत्र में माध्य और मानक विचलन के लिए।
- बाहरी लोगों से सावधान रहें: आउटलेर्स का माध्य और मानक विचलन दोनों पर महत्वपूर्ण प्रभाव पड़ता है, जो संभावित रूप से गणना किए गए z-स्कोर को ख़राब कर देता है।
- डेटा अखंडता सुनिश्चित करें: z-स्कोर की गणना करने से पहले, सुनिश्चित करें कि आपका डेटासेट साफ़ और त्रुटियों से मुक्त है। गलत डेटा प्रविष्टियाँ, डुप्लिकेट, या अप्रासंगिक मान माध्य और मानक विचलन को महत्वपूर्ण रूप से प्रभावित कर सकते हैं, जिससे भ्रामक z-स्कोर बन सकते हैं।
- समय से पहले गोलाई या काट-छांट करने से बचें: एक्सेल दशमलव स्थानों की एक महत्वपूर्ण संख्या को संभाल सकता है, और इन्हें संरक्षित करने से संचयी गोलाई त्रुटियों को रोका जा सकता है जो आपके अंतिम विश्लेषण को विकृत कर सकते हैं।
ऊपर Excel में z-स्कोर की गणना से संबंधित सभी प्रासंगिक सामग्री है। मुझे आशा है कि आपको ट्यूटोरियल उपयोगी लगेगा। यदि आप अधिक एक्सेल टिप्स और ट्रिक्स जानना चाहते हैं, कृपया यहाँ क्लिक करें हजारों से अधिक ट्यूटोरियल्स के हमारे व्यापक संग्रह तक पहुँचने के लिए।
सर्वोत्तम कार्यालय उत्पादकता उपकरण
एक्सेल के लिए कुटूल - आपको भीड़ से अलग दिखने में मदद करता है
एक्सेल के लिए कुटूल 300 से अधिक सुविधाओं का दावा करता है, यह सुनिश्चित करना कि आपको जो चाहिए वह बस एक क्लिक दूर है...
")
ऑफिस टैब - माइक्रोसॉफ्ट ऑफिस में टैब्ड रीडिंग और एडिटिंग सक्षम करें (एक्सेल शामिल करें)
- दर्जनों खुले दस्तावेज़ों के बीच स्विच करने के लिए एक सेकंड!
- हर दिन आपके लिए सैकड़ों माउस क्लिक कम करें, माउस हाथ को अलविदा कहें।
- एकाधिक दस्तावेज़ों को देखने और संपादित करने पर आपकी उत्पादकता 50% बढ़ जाती है।
- क्रोम, एज और फ़ायरफ़ॉक्स की तरह, ऑफिस (एक्सेल सहित) में कुशल टैब लाता है।
")